들어가며
T5(Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer)는 구글에서 개발한
NLP 태스크를 수행하는 머신러닝 모델은 downstream 태스크에서 수행가능한 형태로 텍스트를 입력받게 된다. 이는 넓은 범주로 보았을 때 범용지식(general-purpose knowledge)을 개발하는 한 형태이며, 이를 통해 모델은 텍스트를 이해할 수 있게된다. 여기서 범용지식은 스펠링이나 단어의 의미와 같은 낮은 수준부터, 튜바가 백팩에 들어가기엔 너무 크다는 높은 수준의 지식을 의미한다. 현대 머신러닝에서 이러한 종류의 지식은 거의 명시적으로 수행되지 않는다. 대신, auxiliary task의 한 종류로서 학습하게 된다.
예를들어, word2vec이나 GloVe를 살펴보자. 이들은 비슷한 단어를 비슷한 벡터로 맵핑시키는데, 이러한 벡터들은 co-occurrence 정보를 이용하는 objective를 통해 학습된다.
최근에는 pre-train기법이 유행하고 있는데, 이상적으로는 모델이 범용 능력과 지식을 개발하도록하고, 그 후 downstream task으로 trasnfer 가능하도록한다. CV에서의 transfer learning의 경우 대량의 label data에 대한 supervised learning을 통해 수행되는 반면, NLP는 unsupervised learning을 통해 수행하게 된다. 경험적으로 language model이 강력하다는 점도 있으나, 이를 넘어 unlabeled text를 쉽게 구할 수 있다는 점과, neural networks가 놀라운 scalability(i.e. 더 큰 모델과 데이터가 더 좋은 성능을 냄)를 갖고 있다는 점을 생각하면 이는 매우 매력적이라 할 수 있다.
이러한 시도에는 pre-training objectives, unlabeled data sets, benchmarks, fine-tuning methods 등이 있는데, NLP 분야가 너무 급성장하고 다양한 테크닉이 쓰이다보니 알고리즘끼리의 비교가 어려워지고, 새로운 contribution의 기여를 측정하거나 기존 transfer learning을 이해하기가 어려워진다. 따라서 더욱 엄밀한 이해를 위해 단일화된 transfer learning을 이용, 서로 다른 방법론을 시스템적으로 분석하고 NLP의 한계를 부수고자 한다.
T5는 모든 텍스트 처리 문제를 text-to-text 문제로 취급한다. 즉, 텍스트를 인풋으로 받아 새로운 텍스트를 생성해 아웃풋으로 내보낸다. text-to-text framework을 통해 직접적으로 같은 모델, objective, 학습 절차, 디코딩 절차를 적용할 수 있다. 그리고 QA, 문서요약, 감성분석 등의 문제를 평가하여 T5의 유연한 구조를 살펴본다.
T5의 목적은 새로운 방법론을 제안하는 것이 아닌, NLP의 현재 위치에 대한 포괄적인 관점을 제공하는 것이다. 따라서 본 논문은 주로 기존 기술에 대한 조사, 탐색 및 경험적 비교로 구성된다. 또한, 본 논문에서 제안하는 systematic study (최대 110억 파라미터의 모델을 학습)를 통해 얻은 insight로 확장하여 현재 접근 방식의 한계를 탐구한다. 본 논문에서 제안하는 스케일로 실험하기 위해, Colossal Clean Crawled Corpus을 소개한다. 이는 수백 기가바이트로 이루어진 영어 데이터 셋이다. 그리고 transfer learning의 주요 효용성은 데이터가 부족한 환경에서 pre-training model을 활용할 수 있다는 점을 인식하여 T5의 코드와 데이터 및 모델을 공개한다.
Setup
Model
T5의 encoder-decoder Transformer는 원본의 것을 따르되, 약간의 차이를 둔다. Layer normalization의 경우 activation만 있고 bias가 없는 간단한 버전을 사용하고, residual 바깥에서 적용한다. positional embedding의 경우 relative position embedding를 사용한다. 이는 key와 query사이의 offset에 따라 다른 임베딩을 학습한다. 여기서 offset이란 떨어진 정도를 의미한다고 보면 된다. Relative position embedding 또한 간단한 버전을 사용할 것인데, 각 임베딩이 스칼라값으로 이루어져 logit에 합쳐지게 할 것이다. 효율을 위해 position embedding의 parameter는 모든 레이어가 공유하도록 하고, 레이어 내 각 attention head에서는 다른 position embedding을 학습하여 사용한다.
일반적으로는 고정된 수의 임베딩이 학습되고, 각기 key-query offset간의 범위를 담당하게 된다. 그러나 본 연구에서는 모든 모델에 대해 32개의 임베딩을 사용하고, 이는 로그적으로 증가하여 최대 128의 offset을 갖게한다. 이를 넘는 범위는 같은 값을 같는다.
Relative positional embedding에 대해서는 이곳에 정리가 잘 되어있다.
원본 Transformer와 갖는 구조점 차이점은 앞으로 살펴볼 실험 요소들에 대해 독립적이므로 이는 후속 연구로 남겨놓겠다.
Colossal Clean Crawled Corpus (C4)
T5외에도 대용량 corpus인 Colossal Clean Crawled Corpus (C4)를 통해 LM을 학습시키는데 사용하는 unlabeled data의 크기와 특성, 품질에 대한 영향력을 측정한다. Common Crawl은 공개적으로 사용 가능한 웹 아카이브로, 웹에서 마크업과 non-text content를 제외한 텍스트를 추출하는 기능을 제공한다. 그러나 Common Crawl으로 수집된 데이터의 대부분은 자연어가 아니라 의미없는 텍스트 혹은 메뉴, 에러 메시지, 중복 문자 등의 boiler-plate text로 이루어져있다. 또한, scraped text는 불쾌감을 주는 언어, placeholder text, 소스 코드 등 여기서 고려하는 어떠한 종류의 NLP 태스크에도 도움되지 않는다. 이를 해결하기 위해 다음과 같은 휴리스틱 방법으로 데이터를 정제한다.
- terminal punctuation mark(마침표, 느낌표, 물음표, 따옴표)로 끝나는 문장만 유지한다.
- 5문장 이하로 된 페이지는 버리고, 최소 3단어 이상 사용하는 문장만 사용한다.
- “List of Dirty, Naughty, Obsceneor Otherwise Bad Words”에 있는 단어가 들어간 페이지는 제거한다.
- Javascript 활성화 경고가 포함되어 있으므로 Javascript가 있는 문장은 모두 제거한다.
- Lorem ipsum(로렌 입숨)이 들어간 페이지는 삭제한다.
- 중괄호는 프로그래밍 언어에서 많이 사용하므로 중괄호가 들어간 페이지는 삭제한다.
- 세개의 연속된 문장이 여러번 등장하는 경우 하나만 남기고 지운다.
추가적으로 대부분의 downstream task가 영어로 되어있으므로 langdetect을 이용하여 영어 외의 페이지는 삭제한다.
기존에도 Common Crawl를 source data로 활용한 연구는 많았으나 이전의 연구들은 필터링이 덜 되어있고, 공개되지 않거나, 뉴스 등의 특정 영역에 국한되는 경우, Creative Commons content로만 구성되는 등의 제한이 있다.
본 연구에서 사용되는 C4 기본 데이터셋은 2019년 4월부터 수집하였다. 이는 PLM에서 사용되는 데이터들 보다 10배 정도 크며 (705GB 분량), 앞서말한 필터링으로 인해 질적으로도 훌륭하다 할 수 있다. 다양한 C4의 대체 데이터셋의 영향은 추후 살펴보도록 한다.
Downstream Tasks
일반적인 언어 학습 능력을 측정하기 위해 GLUE와 SuperGLUE text classification meta-benchmarks에 대한 성능을 측정한다. 이는 CNN/Daily Mail abstractive summarization, SQuAD QA, WMT 영어-독일어/프랑스어/루마니아어 번역으로 이루어진다.
사용의 용이함을 위해 모든 태스크는 연속된 데이터를 이어 하나의 태스크로 만든 후 사용한다. 또한, Definite Pronoun Resolution (DPR) data set을 포함시켜 학습한다.
CNN/Daily Mail data set의 경우 entity가 가려져있는데, 이를 비익명화한 버전으로 사용한다. SQuAD의 경우 질문과 context를 넣은 후 정답을 생성하도록 한다.
Input and Output Format
위에 언급한 것처럼 다양한 형태의 태스크를 하나의 모델로 학습하기 위해서는 모든 태스크를 text-to-text 형태로 변환해야 한다. text-to-text는 모델이 context/조건의 형태로 텍스트를 입력받고, output text를 내보내는 것을 의미한다. 이를 통해 pre-training과 fine-tuning 과정 모두 일관된 training objective를 제공한다. 이는 teacher forcing을 이용하여 MLE로 학습하는 식으로 진행된다.
RNN에서 teacher forcing을 사용하는 것은 MLE을 사용해야 하는 것과 같다고 할 수 있다. time step이 2인 경우의 RNN의 objective를 한번 생각해보자. 기존의 구해야 objective는 $\log (p(\mathbf y^{(1)}, \mathbf y^{(2)} \rvert \mathbf x^{(1)}, \mathbf x^{(2)}))$로 표현되는데, 이는 아래와 같이 분해될 수 있다.
\[\log (p(\mathbf y^{(1)}, \mathbf y^{(2)} \rvert \mathbf x^{(1)}, \mathbf x^{(2)})) = \log (p(\mathbf y^{(2)} \rvert \mathbf y^{(1)} \mathbf x^{(1)}, \mathbf x^{(2)})) + \log (p(\mathbf y^{(1)} \rvert \mathbf x^{(1)}, \mathbf x^{(2)}))\]모델은 $t=2$에서 x sequences와 $\mathbf y^{(1)$에 대한 conditional probability $\mathbf y^{(2)$를 최대화하게 된다. 여기서 우리는 teacher forcing을 사용하여 $\mathbf y^{(1)$를 넣어준 것으로, teacher forcing을 사용하지 않으면 $\mathbf x^{(i)$s로만 학습이 진행된다.
학습할 때에는 모델로 하여금 어떠한 태스크를 하는지 구분할 수 있도록 텍스트 앞에 태스크와 연관된 prefix를 붙여 넣어준다. 아래 Figure 1은 이에 대한 예시로 다양한 태스크에 대한 입력 예시와 이에 따른 아웃풋을 보여준다.
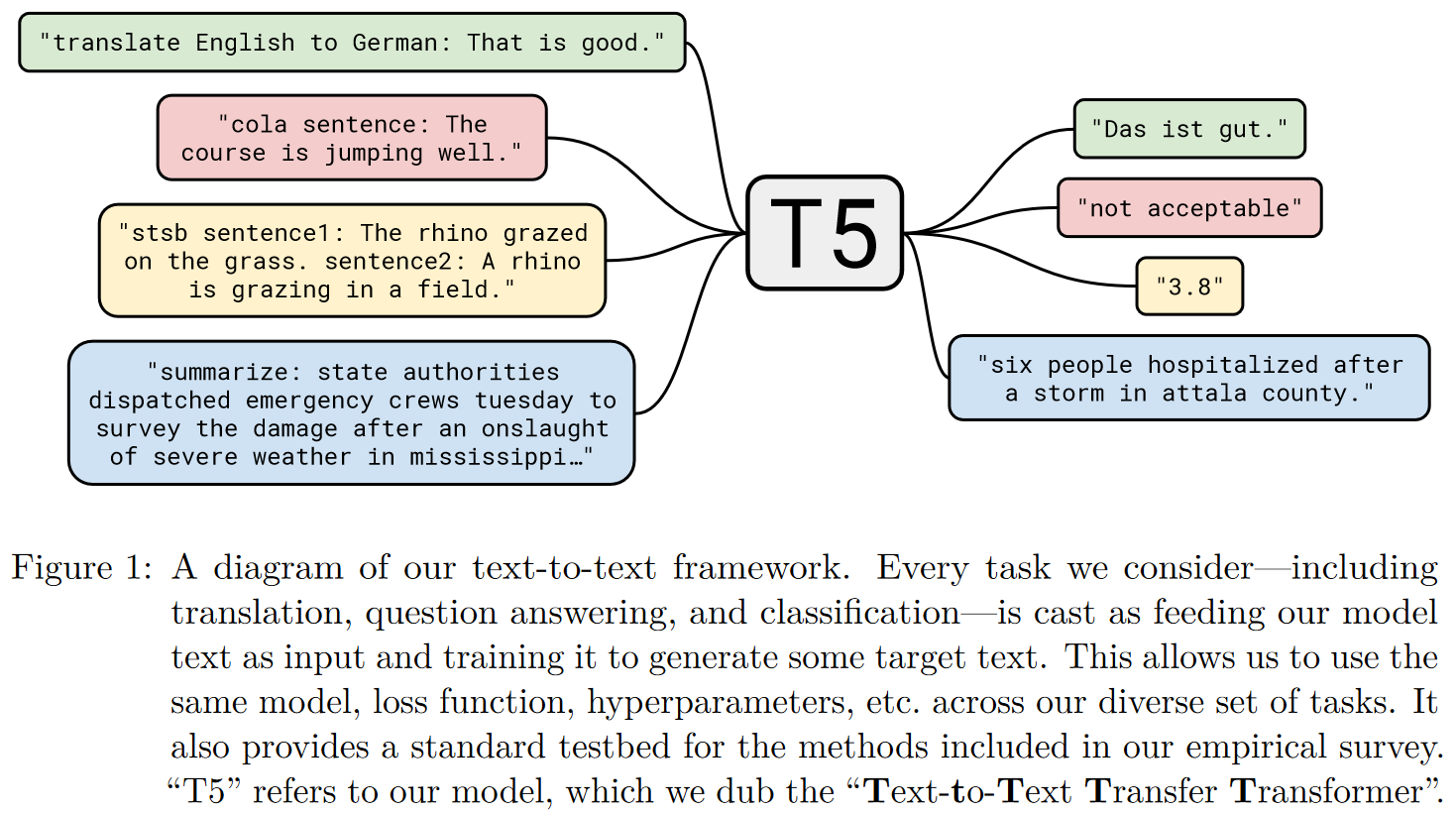
또한, 정답 후보에 없는 텍스트를 내뱉는 경우 이를 오답으로 처리한다. 이외에 논문에서 사용한 GLUE 및 SuperGLUE에 대한 입력 예시는 Appendix D를 참고하자.
T5는 다양한 연구에서 영향을 받았다. 첫번째로는 Natural Language Decathlon이 있다. Natural Language Decathlon은 benchmark 데이터셋을 QA형태로 변환한 뒤 multi-task 형태로 학습한다. 그러나 T5는 여기서 약간의 변형을 가해 개개의 태스크를 각자 학습하고, Natural Language Decathlon처럼 명시적인 QA형태가 아닌 짧은 prefix를 사용한다.
GPT2 또한 이와 유사한 형태이기는 하나 여기서 주로 고려한 것은 encoder에서 인풋이 들어가고 decoder에서 아웃풋을 생성하는 형태이고, zero-shot learning보단 transfer learning에 염두를 둔다.
Keskar et al. (2019b)의 경우 NLP 태스크를 span extraction으로 단일화하는 구조를 갖는다. span extraction은 답변 후보를 인풋에다가 넣은 뒤 이를 뽑아내도록 하는 것이다. T5는 이와 대조적으로 NMT나 요약과 같은 generative tasks가 가능하다.

T5는 대부분의 NLP 태스크를 text-to-text 형태로 변환 가능하다. 그러나 STS-B의 경우에는 조금 어려운데, 이는 regression task이기 때문이다. STS-B의 경우 대부분 0.2 단위로 점수가 매겨지기 때문에, 반올림한 숫자를 string literal로 사용한다. Inference할 때 점수가 1-5사이에 있으면 그대로 사용하지만, 앞선 예시와 같이 후보군에 없는 경우엔 오답으로 처리한다. 이를 통해 STS-B regression problem을 21-class classification problem으로 변환할 수 있다. 여기서 20개가 아닌 21개인 이유는 0.2 단위로 나눴을 때 한쪽이 개구간이 되기 때문으로 보인다.
이와 별개로 Winograd tasks (WNLI from GLUE, WSC from Super-GLUE, DPR data set)는 text-to-text에서 다루기 쉽도록 더욱 단순한 형태로 변환하여 해결한다. Winograd는 passage내 phrase에서 하나 이상의 명사를 가르킬 가능성이 있는 애매모호한 대명사를 포함하는 형태로 이루어진다.
The city councilmen refused the demonstrators a permit because they feared violence.
예시를 보면 they라는 pronoun이 있고, 이것이 city councilmen인지 demonstrators인지 맞추는 것이다. T5는 여기서 애매모호한 pronoun을 강조하는 방식으로 text-to-text에 넣은 후, 이를 맞추게한다. 즉, 이는 다시금 아래로 변환된다.
The city councilmen refused the demonstrators a permit because *they* feared violence.
WSC에선 candidate noun과 이에 대한 True/False를 맞추는 식으로 진행된다. T5에서는 False label에 대한 정답을 확인할 수 없기 때문에, True label을 갖는 example로만 학습을 진행한다. Evaluation에서는 모델이 내놓은 정답이 candidate noun phrase 내 단어의 일부인 경우 정답으로 처리한다. 이 반대의 경우도 마찬가지로 처리한다 (vice versa). 이로 인해 WSC 데이터 중 절반은 사용할 수 없지만, 그래도 DPR덕분에 1,000개 정도의 pronoun resolution example을 추가할 수 있다. DPR은 T5에서 사용하려는 형태와 유사하기 때문에 다른 전처리가 필요 없다. 자세한 변환과정은 Appendix B를 참고하자.
WNLI의 학습과 검증 데이터는 WSC의 검증데이터와 중복되는 양이 많다. 따라서 WNLI로는 학습하지 않고, 이의 검증 데이터에 대해선 평가하지 않는다. 사실 WNLI의 검증 데이터에 대한 생략을 평가하는건 표준적인 일이라 볼 수 있는데, 이는 WNLI의 검증 데이터는 학습 데이터에 대해 adversarial하기 때문이다. 즉, 검증 데이터는 학습 데이터의 반대 label을 갖는 일종의 교란된 버전이다. 그러나 테스트에는 문제가 없기 때문에 이는 보고하도록 한다.
Experiments
앞서 말한 것과 같이 pre-training objectives, model architectures, unlabeled data sets 등의 테크닉에 대하여 empirical survey를 진행, 이들의 중요성과 contribution을 분리하도록 한다. NLP에서의 transfer learning은 빠르게 성장하는 분야이므로 모든 테크닉을 여기서 리뷰할 수는 없다. 이에 대해 관심이 있는 경우 Ruder et al. (2019)를 참고하길 추천한다.
여기서는 한 번에 한 요소만을 변화시키며 성능의 변화를 측정하는데, 이는 특정 unsupervised objective가 특정 모델에서는 잘 작동하는 등의 second-order effects를 놓치게 된다. 그러나 이들을 모두 다 고려하기란 매우 어렵기 때문에 이를 후속 연구로서 남겨둔다.
본 논문의 목적은 가능한 많은 요소들을 고정시킨채로 여러 접근법들을 비교하는 것이다. 따라서 모든 모델을 정확히 구현하는데 힘쓰지 않는다. 예를들면 BERT같은 encoder-only 모델의 경우 generative가 불가능하기 때문에 다른 모델을 사용할 수 없다. 여기서는 이 대신 정신이 유사한 접근 방식을 테스트한다. 예를 들어, BERT의 “masked language model” objective와 유사한 objective를 고려하고, text classification에서 BERT와 유사하게 동작하는 모델 아키텍처를 고려하는 식으로 접근한다. 이는 아래의 Section에서 다시 살펴본다.
Baseline
T5에서 제시하는 베이스라인을 통해 전형적이고 현대적인 절차를 반영하고자 한다. Baseline은 denoising objective에 대해 일반 Transformer를 pre-train하고, 이에 따로 fine-tuning하는 것이다.
Model
T5에서는 일반적인 encoder-decoder를 쓰는 경우가 generative와 classification tasks 모두에서 좋은 결과를 보임을 밝혀냈다. 이에 대해서는 아래에서 다시 살펴볼 것이다.
T5의 baseline모델은 인코더와 디코더 각각 BERT base와 비슷한 사이즈(12 block)로 설정한다. 각 블록 내 feed-forward networks는 $d _{ff}=3022$로 설정한다. key, value는 $d _{kv} = 64$로, 모든 어텐션은 12개의 head를 갖는다. 다른 sub-layer와 임베딩은 $d _{model} = 768$의 차원을 갖는다. 전체적으로는 220M의 파라미터를 갖는다. 이는 BERT base에 비해 2배 가량 많은 것으로, BERT가 인코더만을 갖는 반면 본 baseline은 인코더-디코더 구조이기 때문이다. Dropout은 $0.1$로 모든 레이어에 적용한다.
Training
학습 시 AdaFactor를 사용하며, 인퍼런스 시에는 greedy encoding을 사용한다. 총 학습 step 수는 $2 ^{19} = 524,288$이다. 배치 사이즈는 128이고 문장의 최대길이는 512이다. 그리고 가능한 여러 문장을 엮어 한 배치당 대략 $2^{16}=65,536$개의 토큰이 들어있도록 한다. 따라서 전부 합쳐서 보았을 때 $2^{35} \approx 34 \text{B}$개의 토큰이 된다. 이는 BERT의 137B 토큰이나 RoBERTa 2.2T 토큰에 비하면 한참 작다.
Pre-training 도중에는 inverse square root learning rate schedule을 사용한다. 이는 $1/\sqrt{\max{(n, k)}}$로 계산되며, n은 현재 training iteration, k는 warm-up step의 수이다. k는 $10^4$로 세팅한다. 이로인해 constant learning rate는 첫 $10^4$ step까지는 $0.01$로 유지되고, 그 후 학습이 종료될 때 까지 지수적으로 감소한다. 또한, ULMFiT에서 사용한 triangular learning rate도 실험하였다. Triangular learning rate가 약간 더 나은 결과를 보여주긴하지만 사전에 총 학습 step를 알아야하기 때문에 inverse square root를 사용한다.
Fine-tuning 시에는 모든 태스크에 대해 $2^{18}=262,144$ step을 사용한다. 이는 추가적인 fine-tuning으로 이득을 볼 수 있는 high-resource task와 쉽게 over-fit하는 low-resource tasks 사이에서 trade-off로 선택한 값이다. 배치사이즈와 문장 길이는 그대로 유지한다. 매 5000 step마다 checkpoint를 저장하며, 가장 높은 validation으로 성능을 측정한다. 여러 태스크에 대해 fine-tuning할 경우 각 태스크에 대해 제일 좋은 모델을 따로 저장한다. 일부 경우를 제외하면 성능평가는 validation으로 진행하여 test set을 이용한 model selection을 피한다.
Vocabulary
SentencePiece를 사용하여 텍스트를 WordPiece 토큰으로 변환한다. 모든 모델에서 32000개의 vocab을 사용한다. 또한 번역 태스크도 있으므로 이에 대한 vocab도 필요하다. 따라서 Common Crawl 중 독어, 불어, 루마니아어로 판별된 페이지를 이용하여, 영어의 비중을 10으로하고, 다른 언어를 각 1의 비율로 데이터 셋을 구축한 뒤 vocab을 설정한다.
Unsupervised Objective
Pre-trained model을 학습시킬때는 BERT의MLM과, word dropout regularization technique (Bowman et al., 2015)의 영향을 받아 문장 내 임의의 토큰들을 15%의 확률로 지우는 objective를 사용한다. 지워진 모든 연속된 토큰 (즉, span)은 하나의 sentinel token으로 변경된다. 각 sentinel token은 문장에 유일한 token ID로 할당된다. 이러한 sentinel ID는 사전에 추가되는 speical token으로, 어떠한 wordpiece에도 해당하지 않는다.
따라서 모델이 예측하는 것(target)은 제거된 토큰들(span)이며, 인풋으로 쓰였던 sentinel token과 문장의 마지막임을 알리는 sentinel token으로 구분된다.

제거된 토큰들만을 예측하게 되므로 사전학습시의 계산 비용이 크게 줄게되는 장점이 있다.
Baseline Performance
Architectures
Model Structures
Comparing Different Model Structures
Objectives
unsupervised objective로는 기본적 모델 (autoregressive)과 denoising objective 둘 다를 사용한다. autoregressive 모델의 경우 역사적 배경이 있으며, 여기서 고려하는 구조들과 잘 맞아 떨어지기 때문이다. 예측 전에 접두사를 필요로 하는 인코더-디코더 모델과 prefix LM은 임의의 span을 샘플링하여 예측하도록 한다. Autoregressive 모델의 경우 처음부터 끝까지 예측하도록 한다.
Results
아래 Table 2는 본 논문에서 실험한 결과이다.
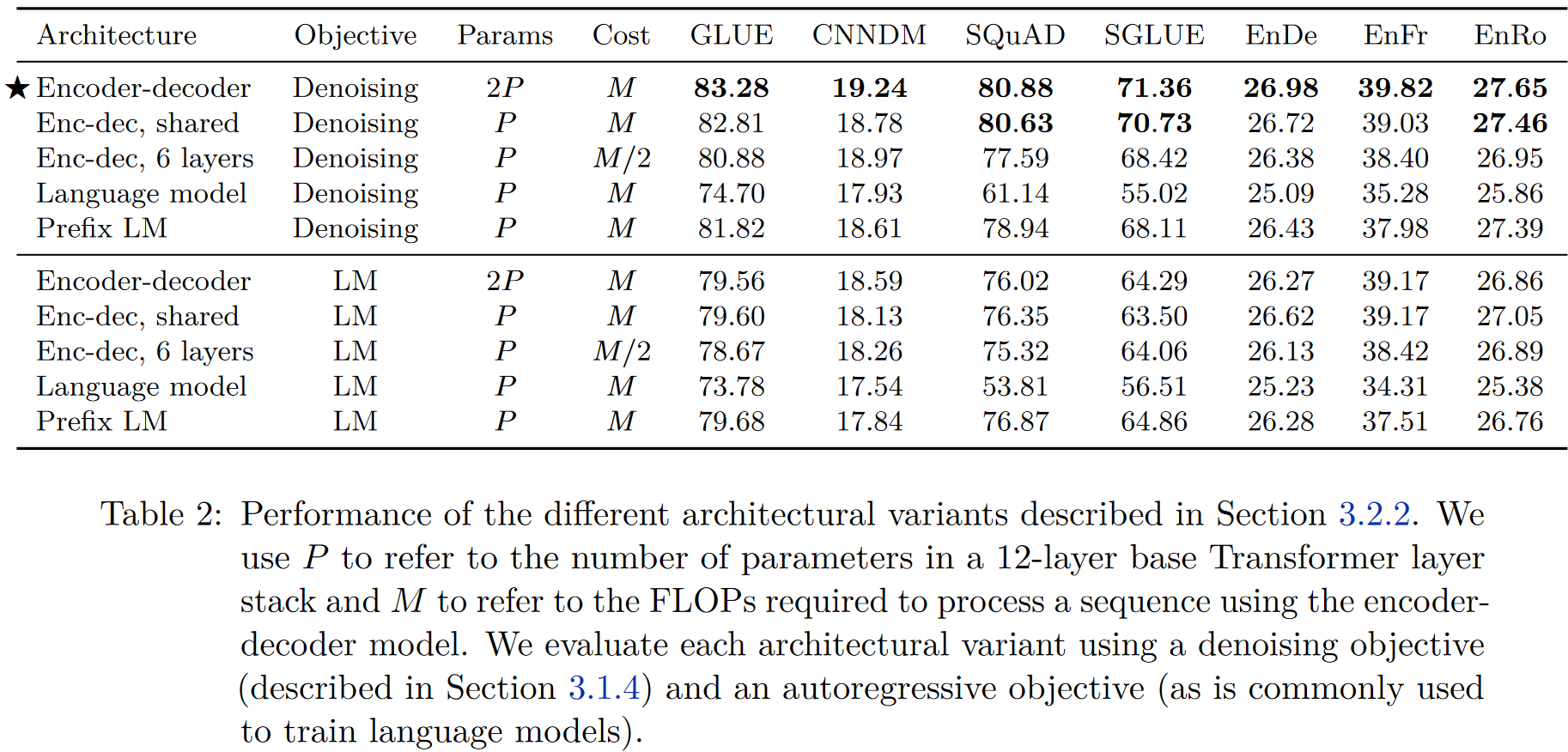
모든 태스크에 대해 인코더-디코더와 denoising objective를 쓴 모델이 가장 성능이 좋았다 (★ Encoder-decoder). 이는 파라미터는 비록 2P로 가장 많지만, 계산 비용 자체는 P개의 파라미터를 갖는 모델과 동일하다. 놀랍게도 파라미터를 공유하는 인코더-디코더 모델의 성능이 이에 가장 근접했다 (Enc-dec, shared). 레이어를 $1/2$만 남긴 모델의 경우 성능이 크게 하락하는 것을 볼 수 있다 (Enc-dec, 6 layers).
파라미터를 공유하는 인코더-디코더 모델의 성능은 ALBERT에서도 이미 확인된 바 있고, XLNet은 아예 이러한 구조와 닮았다. 또한, decoder-only prefix LM의 성능보다 더 좋은 것으로 나타나는데 이는 encoder-decoder attention의 성능을 보여주는 것이라 할 수 있다. 마지막으로 모든 denoising objective는 autoregressive 모델보다 좋은데, 이는 다음장에서 살펴보도록 한다.
Unsupervised Objectives
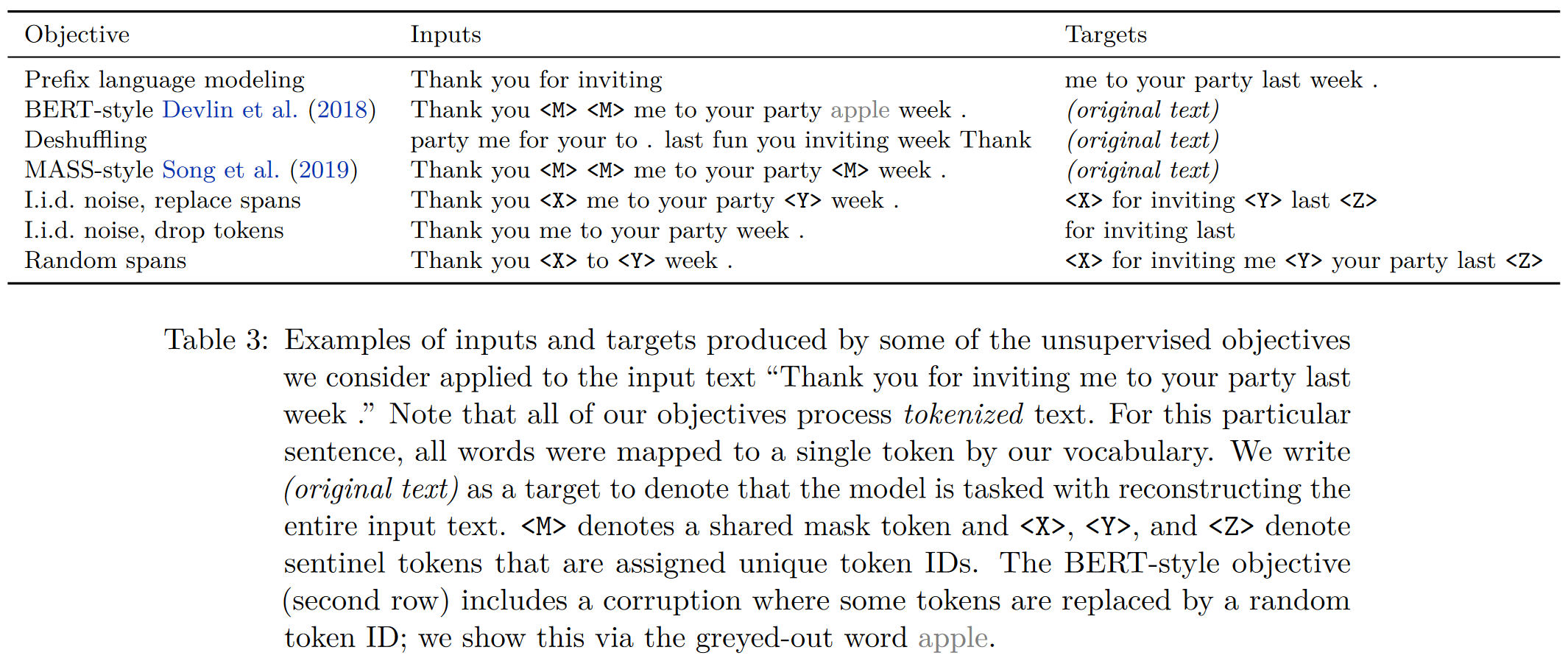
Unsupervised objective는 모델로 하여금 범용 언어 지식을 얻어 downstream tasks에 적용할 수 있게 만드므로 핵심적 요소라 할 수 있다. 따라서 unsupervised objectives 공간의 절차적 탐색 (procedural exploration)을 수행하도록 해보겠다. 앞서 말했듯 모든 모델을 그대로 구현하기보단 본 text-to-text 구조에 맞게끔 약간씩 수정을 할 것이며, 몇몇 경우에는 여러 요소들을 결합하여 사용한다. 모델에 대한 각각의 input과 output은 아래 Table 3에 나와있다.
Disparate High-Level Approaches
우선 첫째로 가장 많이 사용하지만 상이하게 다른 세 가지 objective를 살펴보자.
Prefix language modeling은 텍스트 span을 두 개로 나누어 하나는 인코더의 인풋으로, 하나는 디코더의 아웃풋으로 예측한다.
masked language modeling (MLM)은 BERT에서 사용한 것으로, 15%의 확률로 토큰을 오염시켜 90%는 마스크 토큰으로, 나머지 10%는 임의의 단어로 교체한다. BERT의 경우는 encoder만 있는 모델이므로, pre-training 과정에서 원본 문서를 복원하는데 집중한다. 본 논문에서의 baseline objective는 오염된 토큰을 아웃풋에서 사용하는 점에서 BERT와 다르다. 이러한 차이점 또한 살펴보도록 할 것이다.
마지막은 SummAE에서 사용된 deshuffling objective로 denoising sequential autoencoder에서 사용된다. deshuffling objective는 토큰 시퀀스를 입력받아 섞은 후 섞기 전의 원본을 예측하도록 학습한다. 이들 objective에 대한 예시는 앞서 본 Table 3의 첫 세개의 행에 잘 나타나있다.

위 Table 4는 이들의 성능을 나타낸 것이다.
전체적으로 BERT-style objective의 성능이 제일 좋았으며, prefix LM의 경우 번역 태스크에서 비슷한 성능을 보였다. Deshuffling objective의 경우 성능이 저조하였다.
Simplifying the BERT Objective
focus on exploring modifications to the BERT-style denoising objective. may be possible to modify it so that it performs better or is more efficient in our encoder-decoder text-to-text setup
First, we consider a simple variant of the BERT-style objective where we don’t include the random token swapping step: MASS식 second, avoid predicting the entire uncorrupted text span since this requires self-attention over long sequences in the decoder
- First, instead of replacing each corrupted token with a mask token, replace the entirety of each consecutive span of corrupted tokens with a unique mask token. Then, the target sequence becomes the concatenation of the “corrupted” spans, each prefixed by the mask token used to replace it in the input (pre-training objective we use in our baseline)
- Second, a variant where simply drop the corrupted tokens from the input sequence completely and task the model with reconstructing the dropped tokens in order.
=> potentially attractive since they make the target sequences shorter and consequently make training faster.
An empirical comparison of the original BERT-style objective to these three alternatives is shown in Table 5 -> all of these variants perform similarly
only exception was that dropping corrupted tokens completely produced a small improvement in the GLUE score thanks to a significantly higher score on CoLA (60.04, compared to our baseline average of 53.84, see Table 16) -> due to the fact that CoLA involves classifying whether a given sentence is grammatically and syntactically acceptable, and being able to determine when tokens are missing is closely related to detecting acceptability. However, dropping tokens completely performed worse than replacing them with sentinel tokens on SuperGLUE.
Varying the Corruption Rate
compare corruption rates of 10%, 15%, 25%, and 50% in Table 6. -> the corruption rate had a limited effect on the model’s performance
The only exception is that the largest corruption rate we consider (50%) results in a significant degradation of performance on GLUE and SQuAD. Using a larger corruption rate also results in longer targets, which can potentially slow down training.
=> Based on these results and the historical precedent set by BERT, we will use a corruption rate of 15% going forward
Corrupting Spans
We now turn towards the goal of speeding up training by predicting shorter targets. The approach we have used so far makes an i.i.d. decision for each input token as to whether to corrupt it or not.
Since we are using an i.i.d. corruption strategy, it is not always the case that a significant number of corrupted tokens appear consecutively
To test this idea, we consider an objective that specifically corrupts contiguous, randomly- spaced spans of tokens. This objective can be parametrized by the proportion of tokens to be corrupted and the total number of corrupted spans. The span lengths are then chosen randomly to satisfy these specified parameters.
For example, if we are processing a sequence of 500 tokens and we have specified that 15% of tokens should be corrupted and that there should be 25 total spans, then the total number of corrupted tokens would be 500 × 0.15 = 75 and the average span length would be 75/25 = 3. 연속해서 오염할 토큰의 길이.
We use a corruption rate of 15% in all cases and compare using average span lengths of 2, 3, 5 and 10.
- average span length of 10 slightly underperforms
- sing an average span length of 3 slightly (but significantly) outperforms the i.i.d. objective on most non-translation benchmarks.
- span-corruption objective also provides some speedup during training compared to the i.i.d.
Discussion
the most significant difference in performance we observed was that denoising objectives outperformed language modeling and deshuffling for pre-training.t did not observe a remarkable difference across the many variants of the denoising objectives we explored. However, different objectives (or parameterizations of objectives) can lead to different sequence lengths and thus different training speeds => implies that choosing among the denoising objectives we considered here should mainly be done according to their computational cost. also suggest that additional exploration of objectives similar to the ones we consider here may not lead to significant gains for the tasks and model we consider. Instead, it may be fortuitous to explore entirely different ways of leveraging unlabeled data.
Pre-training Data set
Like the unsupervised objective, the pre-training data set itself is a crucial component of the transfer learning pipeline. To probe more deeply into the impact of the pre-training data set on performance, in this section we compare variants of our C4 data set and other potential sources of pre-training data.
Unlabeled Data Sets
In creating C4, we developed various heuristics to filter the web-extracted text from Common Crawl (see Section 2.2 for a description). We are interested in measuring whether this filtering results in improved performance on downstream tasks, in addition to comparing it to other filtering approaches and common pre-training data sets.
C4 As a baseline, Unfiltered C4: measure the effect of the heuristic filtering (deduplication, removing bad words, only retaining sentences, etc.) but still use langdetect to extract English text.
이해안됨. A drawback to only pre-training on a single domain is that the resulting data sets are often substantially smaller. Similarly, while the WebText-like variant performed as well or better than the C4 data set in our baseline setting, the Reddit-based filtering produced a data set that was about 40× smaller than C4 despite being based on 12× more data from Common Crawl. Note, however, that in our baseline setup we only pre-train on 235 ≈ 34B tokens, which is only about 8 times larger than the smallest pre-training data set we consider. We investigate at what point using a smaller pre-training data sets poses an issue in the following section.
Training Strategy
이후로부터는 fine-tuning에 관련된 전략을 알아보도록 한다.
Fine-tuning Methods
low-resource 상황에서 모델 내 모든 파라미터를 학습 시키는 것이 모델에 어떤 영향을 미치는지 오랫동안 갑론을박이 있었다. text classification tasks에 대헌 transfer learning을 수행할 때에는 PLM은 고정시킨채로 classifier만이 학습시키는게 좋다는 연구 결과가 있었다. 그러나 본 T5의 인코더-디코더 모델에선 디코더 전체를 학습시켜야되기 때문에 바로 적용시키기는 어렵다. 대신 인코더-디코더 중 일부분만 학습시키는 식으로 진행을 한다.
첫번째로 시도할 방법은 adapter layers (Houlsby et al., 2019; Bapna et al., 2019)로, Transformer의 각 블록 내의 feed-forward network에 dense-ReLU-dense 블록을 추가하는 방식이다. 그 후 fine-tuning 시에는 모델에 추가한 adapter layer와 layer normalization 파라미터만 업데이트한다. Adapter layer의 주 파라미터는 inner dimensionality $d$로, 얼마만큼의 파라미터가 모델에 추가되는지를 결정한다.
두번째 방법은 ULMfit에서 제안한 gradual unfreezing이다. Gradual unfreezing은 말 그대로 fine-tuning을 진행할수록 얼려놓은 파라미터를 풀고 학습시키는 것이다. 이를 T5의 인코더-디코더 모델에 학습시키기 위해 인코더와 디코더를 상단 레이어부터 동시에 unfreeze한다. 12개의 레이어를 갖고 $2^{18}$ step만큼 학습시키므로, 한번 당 $2^{18}/12$ step으로 상단 레이어부터 학습하고 그 후 다음 레이어를 풀어 학습한다.
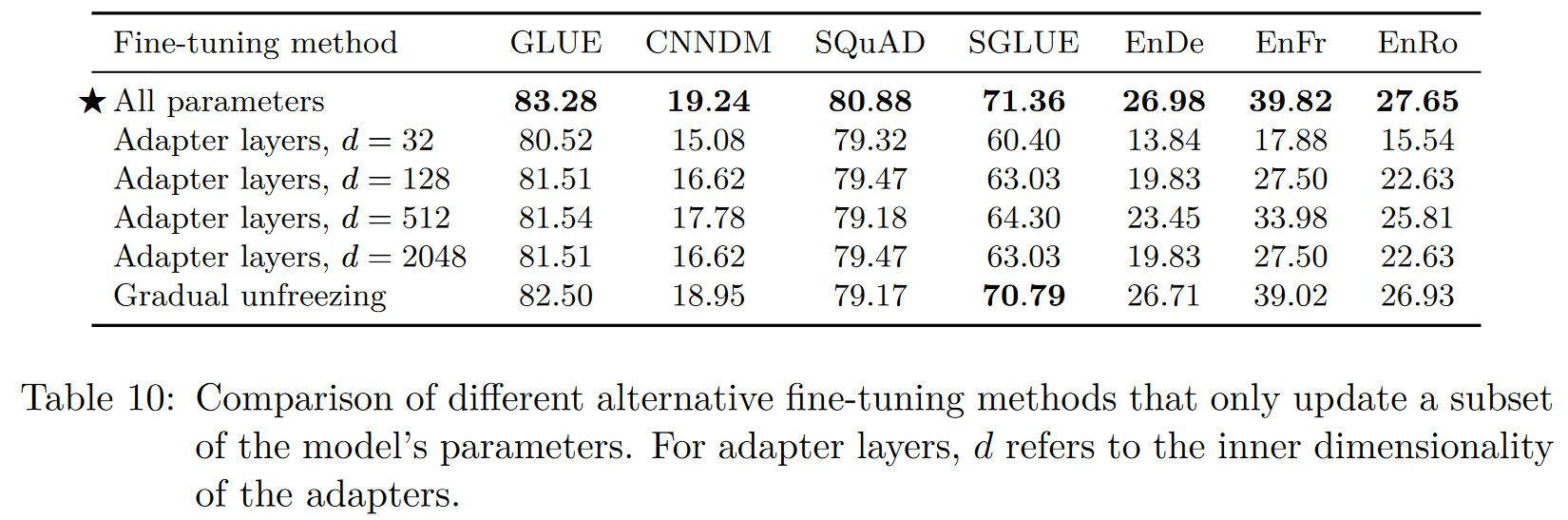
위 Table 10은 fine-tuning 전략에 대한 결과이다.
Adapter layer의 경우 하이퍼 파라미터 inner dimensionality에 대해 다양한 세팅으로 실험을 진행하였다. Adapter layer를 제안한 논문과 비슷하게 SQuAD와 같은 lower-resource tasks에서는 $d$값을 작게하는 것이 유용한 반면, high resource tasks에서는 높은 $d$값이 더 도움이 된다. 이를 통해 차원을 태스크 사이즈에 적절하게 유지하는한 적은 파라미터가 유용함을 확인할 수 있다. 단, 여기서 진행한 GLUE와 SuperGLUE의 경우 각각의 태스크가 low-resource라 하더라도, 이를 전부 결합하여 진행하므로 $d$를 크게 유지하는 것이 도움이 된다.
Gradual unfreezing의 경우 성능이 약간씩 떨어졌으며, 학습 시 약간의 속도향상을 얻었다고 한다.
Multi-task Learning
지금까지는 하나의 unsupervised learning task를 수행한 뒤 개개의 downstream task에 fine-tuning을 수행하였다. 이번에는 multi-task learning을 수행해보도록 한다.
multi-task learning은 다양한 태스크를 같은 모델에 대해 동시에 수행하는 것으로, 모델과 대부분의 파라미터가 태스크에 대해 공유된다. 이번에는 이를 다소 완화하여, 각 태스크에 대해 잘 동작하는 파라미터 세팅을 찾는 식으로 바꿔본다. 즉, 여러 태스크에 하나의 모델을 학습시킬 순 있지만, 성능 측정시에는 각 태스크마다 다른 체크포인트를 사용하도록 하는 것이다. 이를 통해 지금까지 살펴본 pre-train 후 fine-tune 방법론에 비교하여 좀 더 균등한 기반을 제공한다.
T5에서의 multi-task learning은 단순히 데이터셋을 섞는 것으로 달성한다. 이는 LM에 대한 학습 또한 multi-task learning으로서 수행할 수 있다는 뜻이기도 하다. 반면 다른 모델은 task에 연관된 네트워크를 추가하던가 다른 손실 함수를 추가하여 달성한다.
Arivazhagan et al. (2019)에서 지적한 바와 같이 multi-task learning에서 가장 중요한 것은 모델을 학습시키는데 사용하는 각각의 태스크의 데이터셋 비율이다. 여기서는 모델을 under/over-train하지 않는다. 이는 각 태스크를 잘 수행하기 위해 모델이 충분히 데이터를 보길 원하지만, 그렇다고 너무 많이 봐서 학습 데이터를 기억하는 것을 방지하기 위함이다. 각 태스크의 데이터 비율을 정확하게 설정하는 방법은 데이터의 크기, 학습의 난이도 (즉, 태스크를 효과적으로 수행하기 전에 얼마나 많은 데이터를 봐야 하는지), 정규화 등 다양한 요인에 따라 달라질 수 있다.
추가적인 이슈로는 task interference나 negative transfer와 같이 한 태스크에서 좋은 성능을 달성할 경우 다른 태스크에서 성능이 내려가는 것들이 있다.
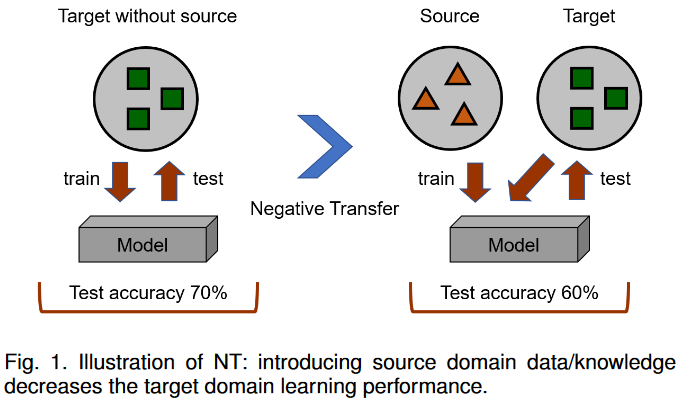
negative transfer
아래 그림과 같이 transfer learning에서 source domain에 대한 데이터/지식을 사용할 때 의도치않게 target domain에서의 성능을 줄이는 것을 의미한다.
이러한 점들을 고려하여 각 태스크로부터 오는 데이터의 비율을 고르는 전략을 세워보도록 한다.
Examples-proportional mixing
모델이 얼마나 빠르게 오버피팅하는지 결정하는 중요한 요인은 데이터의 크기이다.
따라서 데이터를 섞는 비율은 각 태스크의 데이터 크기에 비례하여 샘플링하는 것이 자연스럽다.
이는 모든 태스크에 대한 데이터를 concat하고 무작위로 샘플링하는 것과 같다.
그러나 LM 데이터가 다른 태스크의 10배는 넘는 데이터를 갖고 있으므로, 여기서 단순히 샘플링만 한다면 대다수가 unsupervised denoising task에 대한 데이터일 것이다.
unsupervised denoising task 데이터가 없다고해도, WMT Eng-Fr과 같은 데이터가 너무 커서 배치의 대다수를 차지할 것이다.
이를 해결하기 위해 데이터 사이즈의 임의적인 “한계”를 정해놓고 비율을 설정한다.
특정 태스크 n에 대해, 이의 데이터 사이즈를 $e _n$이라 하자.
그렇다면 학습동안, $K$의 데이터 사이즈 제한을 갖는, $m$번째 태스크로부터 데이터를 샘플링할 확률은 $r _m = \min{(e _m, K)}/ \sum{\min{(e _n, K)}}$가 된다.
Temperature-scaled mixing
또 다른 방법은 혼합 비율 간의 temperature을 도입하는 것이다.
이는 multilingual BERT에서도 도입된 방법으로, 모델이 low-resource에서도 충분히 학습되도록 보장한다.
각 태스크에 대한 mixing rate $r _m$을 temperature $T$의 제곱근만큼 올리고, renormalize하여 이들의 합이 1이 되도록 한다.
따라서 $T=1$일 경우 이는 Examples-proportional mixing과 같게되며, $T$가 커질수록 아래서 보게 될 equal mixing과 동일해진다.
데이터 사이즈 제한은 $K$는 그대로 유지하되 큰 값 ($K=21$)으로 잡는다.
이는 temperature가 증가할수록 큰 데이터의 mixing rate가 감소하기 때문이다.
$K$는 $r _m$을 구하는데 사용되며, 그 이후 temparature를 적용한다.
Equal mixing
균등분포를 이용하여 데이터를 추출한다.
일반적으로는 좋지 않은 방법(suboptimal)이며, low-resource에서는 빠르게 오버피팅하고 high-resource에는 언더피팅한다.
이는 데이터를 섞는 비율이 안 좋을 경우에 얼마나 잘 못될수 있는지에 대한 레퍼런스로 둔다.
본 모델의 baseline pre-train-then-fine-tune가 동일선상에 놓기 위해 학습 스텝은 $2^{19}+2^{18}=786432$로 세팅한다. 이에 대한 결과는 아래 Table 11에 나와있다.
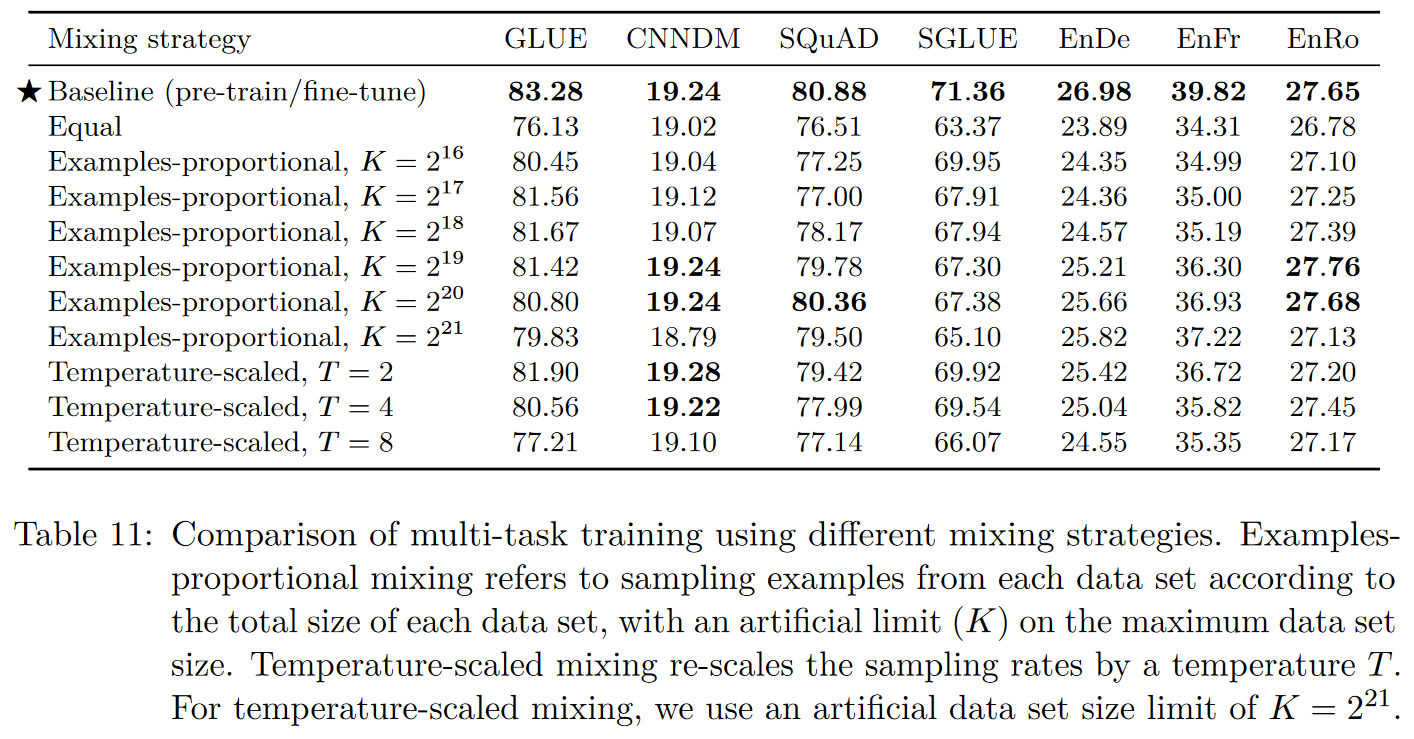
일반적으로는 multi-task training의 성능이 안 좋은 것으로 나타났다. equal mixing의 경우 특히 성능을 매우 감소시켰으며, 이는 아마 오버피팅(low-resource), 언더피팅(high-resource), LM 성능의 문제로 예상된다. 앞서 LM 학습 또한 multi-task learning의 일종으로 볼 수 있다고 한 것으로 보아, LM 또한 multi-task setting에서 학습시킨 것으로 보인다.
examples-proportional mixing의 경우 모델이 잘 동작하는 $K$값이 존재하였으며, 크거나 작은 $K$값은 성능을 저해하였다. 이에 대한 예외로는 WMT Eng-Fr로, high-resource task이기 때문에 $K$값이 커질 수록 좋은 성능을 보였다.
마지막으로 emperature-scaled mixing의 경우 대부분의 태스크에서 비슷한 성능을 보였다.
Combining Multi-Task Learning with Fine-Tuning
extend this approach by considering the case where the model is pre-trained on all tasks at once but is then fine-tuned on the individual supervised tasks (MT-DNN)
1번이 정확히 어떻게 되는건지
three variants of this approach
- Multi-task pre-training + fine-tuning: simply pre-train the
model on an examples-proportional mixture with an artificial data set size limit of K = 219
before fine-tuning it on each individual downstream task
- helps us measure whether including the supervised tasks alongside the unsupervised objective during pre-training gives the model some beneficial early exposure to the downstream tasks
- also hope that mixing in many sources of supervision could help the pre-trained model obtain a more general set of “skills” (loosely speaking
- Leave-one-out multi-task training: pre-train the model on the same examples-proportional mixture (with K = 219) except that we omit one of the downstream tasks from this pre-training mixture. Then, we fine-tune the model on the task that was left out during pre-training
- Supervised multi-task pre-training: Pre-train on an examples-proportional mixture of
all of the supervised tasks we consider with K = 219
- Since other fields (e.g. computer vision) use a supervised data set for pre-training, we were interested to see whether omitting the unsupervised task from the multi-task pre-training mixture still produced good results.
suggests that using fine-tuning after multi-task learning can help mitigate some of the trade-offs between different mixing rates described in Section 3.5.2
Scaling
“You were just given 4× more compute. How should you use it?”
16 and 32 layers가 왜 x2, x4인지 모르겠음
Note that when increasing the number of pre-training steps, we are effectively including more pre-training data as C4 is so large that we do not complete one pass over the data even when training for 223 steps.
However, we also note that the results of Section 3.5.3 suggest that fine-tuning after multi-task pre-training can mitigate some of the issues that might arise from choosing a suboptimal proportion of unlabeled data. -> 언제?
First, the standard baseline model, which was pre-trained on 235 ≈ 34B tokens; second, the baseline trained instead for about 1 trillion tokens (i.e. the same amount of pre-training used for T5), which we refer to as “baseline-1T”; and third, T5-Base. Note that the differences between baseline-1T and T5-Base comprise the “non-scaling” changes we made when designing T5. As such, comparing the performance of these two models gives us a concrete measurement of the impact of the insights from our systematic study. -> 차이를 잘 모르겠음
- Relative embedding이 어텐션마다 존재하는거임?
- 로컬 어텐션에서 못 본 것을 어떻게 다음 레이어에서 확인?
{: .align-center}{: width=”500”}