
SEQUENCE-TO-SEQUENCE MODELING WITH NN.TRANSFORMER AND TORCHTEXT
Introduction
이번 튜토리얼은 nn.Transformer를 이용하여 sequence-to-sequence 모델을 어떻게 학습시키는지 알아보겠습니다.
Pytroch 1.2 release는 Attention is All You Need에 기반한 표준 transformer 모듈을 포함합니다. transformer 모델은 더욱 parallelizable하면서 다양한 sequence-to-sequence에 우월함이 증명되었습니다. nn.Transformer는 전적으로 attention mechanism(최근 nn.MultiheadAttention으로 구현된 다른 모듈)에 의존하여 인풋과 아웃풋사이의 global dependency를 추출합니다. nn.Transformer은 고도로 모듈화되어 이 튜토리얼의 nn.TransformerEncoder와 같은 단일 component가 쉽게 결합/적용될 수 있게합니다.
![]()
원문은 다음을 참고해주세요. 저번과 마찬가지로 역자 주석은 이렇게 citation으로 달겠습니다. 본 튜토리얼의 colab파일은 다음과 같습니다. https://github.com/InhyeokYoo/PyTorch-tutorial-text/blob/master/SEQUENCE_TO_SEQUENCE_MODELING_WITH_NN_TRANSFORMER_AND_TORCHTEXT.ipynb
Define the model
이번 튜토리얼에서는 language modeling 작업에 대해 nn.TransformerEncoder을 학습시켜보겠습니다. lanuage modeling 작업은 따라오는 a sequence of words에 대한 given word (혹은 sequence of words)의 그럴듯한 확률(probability for the likelihood)을 할당하는 것입니다. A sequence of tokens는 먼저 embedding layer로 전달된 후, 단어 순서에 대한 정보를 전달하기 위해 positional encoding layer로 전달됩니다. nn.TransformerEncoder는 여러개의 nn.TransformerEncoderLayer으로 이루어져 있습니다. 인풋 시퀀스와 함께, _square attention mask_를 필요로 하는데, 이는 nn.TransformerEncoder 안의 self-attention layer가 오직 이전에 등장한 단어들에만 주목(attend)하도록 되어있기 때문입니다. language modeling 작업에서는 미래 위치에 있는 어떠한 토큰이던지 전부 가려집니다(maksed). nn.TransformerEncoder는 마지막 linear layer와 log-Softmax를 거쳐 단어를 예측하게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import TransformerEncoder, TransformerEncoderLayer
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
PositionalEncoding 모듈은 sequence 내 토큰의 상대적 혹은 절대적 위치에 관한 정보를 집어넣습니다. Postional encoding은 embedding과 같은 차원을 갖아 이 둘을 더할 수 있습니다. 여기서 우리는 sine과 cosine을 사용하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
저번과 마찬가지로 어렵습니다. 설명을 해놓을거면 똑바로 해놓던가… 튜토리얼 느낌이 나질 않네요. 한번 자세히 살펴봅시다.
Positional Encoding
Positional Encoding 먼저 보겠습니다.앞서 설명했듯 transformer는 embedding layer를 통과한 후 positional encoding layer를 통과합니다. transformer는 RNN구조를 탈피했기 때문에, positional encoding을 통해 단어의 순서에 대한 정보를 주는 것입니다.
positional encoding은 다음과 같은 함수를 이용해 진행됩니다.
$$ PE_{(pos, 2i)} = \sin (pos/10000^{2i/d_{model}}) \\ PE_{(pos, 2i+1)} = \cos (pos/10000^{2i/d_{model}}) $$
여기서 pos는 embedding vector 내에서 위치를, i는 단어의 위치를 나타냅니다. 이를 문장의 개념에서 생각해보면 문장의 단어들의 embedding vector matrix와, positional encoding matrix를 더해주는 것으로 이해할 수 있습니다.
코드를 보면 좀 더 명확합니다. 우선 encoding matrix와 positional encoding matrix를 더해줄 큰 matrix를 0으로 초기화합니다. 이를pe에 할당합니다. 이후 position역할을 해줄 $pos$ sequence를 생성합니다.
1
2
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
그리고
div_term에 $1/10000^{2i/d_{model}}$ sequence를 생성하고position과 곱해 $PE$를 만들면 됩니다.
1
2
3
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
그러나 여기서 굳이 $\exp(\log(…))$의 형태로 한 것은 잘 이해가 가질 않네요.
positional encoding과 embedding이 결합된 matrix
pe는 [max len, d_model]차원이 됩니다. 이를 [1, max len, d_model]로 만들고, transpose를 통해 [max len, 1, d_model]로 만듭니다. 일반적으로 RNN에서 사용하는 input모양과 닮았네요. 1은 batch size으로 보입니다.
이후엔self.register_buffer에 이 matrix를 할당해줍니다.self.register_buffer는parameter는 아니기 때문에 grad에 영향을 받진 않지만,state_dict안에 저장됩니다. 또한model.parameters()를 통해서 return받지도 않습니다.
1
2
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer = ('pe', pe)
forward에서는 embedding matrixx와pe를 더한 값을 return합니다.pe는 max_len에 대해 모든 값을 계산한 것이기 때문에, input의 length(x.size(0))만큼만 뽑아서 더해줍니다.
1
2
3
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
사실상 forward는 필요가 없고, 따라서
nn.Module을 상속받을 이유가 없습니다. 이는 parameter가 없어 gradient가 흐르지 않기 때문입니다.
1
2
3
model = PositionalEncoding(512)
for param in model.parameters():
print(param) # Empty!
nn,TransformerEncoderLayer
API에 따르면
nn.TransformerEncoder는 N encoder layers의 stack이라고 되어 있습니다. 따라서TransformerEncoderLayer를 보겠습니다.

TransformerEncoderLayer는 self-attn(MultiheadAttention)과 feedforward로 구성되어 있습니다. parameter는 다음과 같습니다.
- d_model: Encoder에서 input/output의 차원. Embedding vector의 크기도 d_model이 됨. 논문에선 512.
- nhead: multiheadattention에서 head의 갯수로, 벡터를 nhead만큼 나누어 병렬로 attention을 진행.
- dim_feedforward: transformer 내부 FF의 hidden 차원 (default=2048).
- dropout: the dropout value (default=0.1).
- activation: the activation function of intermediate layer, relu or gelu (default=relu).
forward의 Parameter는 다음과 같습니다.
- src: Encoder에게 feed할 sequence
- tgt: Decoder에게 feed할 sequence
- src_mask: the additive mask for the src sequence (optional).
- tgt_mask: the additive mask for the tgt sequence (optional).
- memory_mask – the additive mask for the encoder output (optional).
- src_key_padding_mask: the ByteTensor mask for src keys per batch (optional).
- tgt_key_padding_mask: the ByteTensor mask for tgt keys per batch (optional).
- memory_key_padding_mask: the ByteTensor mask for memory keys per batch (optional).
생성자를 살펴보면 다음과 같이 되어 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu"):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = Linear(d_model, dim_feedforward)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model)
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
self.activation = _get_activation_fn(activation)
앞서 언급한 FFN과 seft-attention이 있는 것을 확인할 수 있습니다.
nn.MultiheadAttention
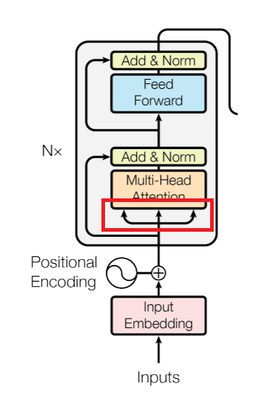
앞선 embedding + positional encoding의 결과는 위 그림의 빨간색 네모와 같이 세 개로 분리되어 multihead attention에 들어가게 됩니다. API 문서에서는 다음과 같이 input의 dimension을 설정해놨습니다.
Inputs:
- query: ($L$, $N$, $E$) where L is the target sequence length, N is the batch size, E is the embedding dimension.
- key: ($S$, $N$, $E$), where S is the source sequence length, N is the batch size, E is the embedding dimension.
- value: ($S$, $N$, $E$) where S is the source sequence length, N is the batch size, E is the embedding dimension.
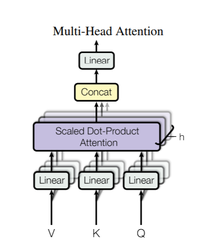
MultiheadAttention은 위와 같이 Scaled Dot-Product Attention 여러개로 구성되어 있습니다. 그림에서 보이는 h가 바로 앞서 보았던
TransformerEncoder의 Param.nhead를 의미합니다. $Q, K, V$는 모두 같은 것으로, input vector를 nhead로 나눈 것이 이들의 차원이됩니다. 원문에서는 d_model이 512이 이고, nhead(h)가 8이므로, $Q, K, V$의 차원은 $512/8=64$가 됩니다. PyTorch에서 이 코드를 찾아봤으나,nn.functional.multi_head_attention_forward을 통해 접근하고, 코드는 찾지 못하였습니다.
그리고 Scaled Dot-Product Attention내에서 self attention이 일어나게 됩니다. 이를 수식으로 표현하면 다음과 같습니다.
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O \\ \text{where } head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
Load and batch data
학습과정은 torchtext내의 Wikitext-2 dataset를 이용합니다. vocab 객체는 학습 데이터에 기반하여 만들어지고, token을 tensor로 numericalize하는데 이용됩니다. Sequential 데이터로부터 시작하여, batchify() 함수는 데이터셋을 column으로 정렬하여 데이터가 batch_size 크기의 배치로 나눠진 후 남은 토큰을 제거합니다. 예를 들어, 알파벳 sequence와 4의 batch size인 경우, 우리는 알파벳을 6의 길이의 4개의 sequence로 나타낼 것입니다.
이러한 컬럼은 모델에 의해 독립적으로 처리됩니다. 즉, G와 F의 관계는 학습될 수 없으나 더욱 효율적인 batch processing을 가능케합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import torchtext
from torchtext.data.utils import get_tokenizer
# Field 객체 생성
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),
init_token='<sos>',
eos_token='<eos>',
lower=True)
# splits 메소드로 데이터를 생성
train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)
# vocabulary 생성
TEXT.build_vocab(train_txt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def batchify(data, batch_size):
data = TEXT.numericalize([data.examples[0].text])
# dataset을 batch_size로 나눔
nbatch = data.size(0) // batch_size
# 나머지는 전부 잘라버림
data = data.narrow(0, 0, nbatch * batch_size)
# batch size batches로 균등하게 나눔
data = data.view(batch_size, -1).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_txt, batch_size)
val_data = batchify(val_txt, eval_batch_size)
test_data = batchify(test_txt, eval_batch_size)
마찬가지로 자세히 살펴보겠습니다. 이전시간에서 보았듯,
Field는 텍스트 데이터를 tensor로 변환하는 지시사항(instructions)과 datatype을 정의합니다.
1
2
3
4
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),
init_token='<sos>',
eos_token='<eos>',
lower=True)
그 후엔 torch.data.Dataset.splits을 이용하여 train, test, validation으로 분리합니다. splits 메소드는 text_field를 인자로 받으며, 이는 text data에 쓰일 field를 의미합니다.
1
train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)
이후엔 field 객체의 build_vocab 메소드를 통해 사전을 생성하면 끝입니다.
1
TEXT.build_vocab(train_txt)
batchify()는 앞서 언급했듯, 정해진 batch size로 데이터셋을 나누는 역할을 합니다.Field의numericalize는 batch로 들어온 데이터를 field를 이용해Variable로 바꾸는 역할을 합니다.numericalize는 arr _(List[List[str]], or tuple of (List[List[str]], List[int]))_을 인자로 받고, str은 tokenize되고 pad된 example입니다.
1
data = TEXT.numericalize([data.examples[0].text])
그리고 nbatch를 계산한 후, narrow를 이용해 indexing하고, contiguous를 통해 데이터값을 가져옵니다. contiguous는 데이터의 idx를 가져오는 것이 아닌, 실제 데이터 값을 복사합니다. 이곳을 참조.
1
2
3
nbatch = data.size(0) // batch_size
data = data.narrow(dim=0, start=0, length=nbatch * batch_size) # data[0:nbatch * batch_size, :] 과 동일
data = data.view(batch_size, -1).t().contiguous()
Functions to generate input and target sequence
get_batch() 함수는 transformer model을 위한 input과 target sequence를 생성합니다. 이는 source data를 bptt길이의 뭉터기로 세분화합니다. Language model 작업을 위해서 모델은 뒤따라오는 다음 단어들을 Target으로 필요로 합니다. 예를 들어, bptt값이 2라고했을 때, i=0인 시점에서 다음 두 Variable을 얻을 것입니다.
![]()
뭉터기로 자르는 작업은 dimension 0을 따라서 진행되고, Transformer 모델 내의 S 차원과 일치합니다. Batch 차원 N은 dimension 1을 따릅니다.
1
2
3
4
5
6
bptt = 35
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1) # cross entropy에 집어넣을 것이니 차원을 미리 조정
return data, target
Initiate an instance
모델은 아래의 hyperparameter를 따라 세팅됩니다. 사전의 크기는 vocab object의 길이와 같습니다.
1
2
3
4
5
6
7
ntokens = len(TEXT.vocab.stoi)
emsize = 200
nhid = 200
nlayers = 2
nhead = 2
dropout = 0.2
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
Run the model
CrossEntropyLoss를 통해 loss를 계산하고, SGD를 optimizer로 사용하겠습니다. 초기 lr은 0.5입니다. StepLR을 사용하여 epochs마다 lr을 조정하겠습니다. 학습과정동안 nn.utils.clip_grad_norm_를 사용하여 exploding을 방지하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
import time
def train():
model.train()
total_loss = 0
start_time = time.time()
ntokens = len(TEXT.vocab.stoi)
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
optimizer.zero_grad()
output = model(data)
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
log_interval = 200 #
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print(f'| epoch {epoch:3} | {batch:5}/{len(train_data) // bptt:5} batches | '
f'lr {scheduler.get_lr()[0]:02.2} | ms/batch {elapsed * 1000 / log_interval:5.2} | '
f'loss {cur_loss:5.2} | ppl {math.exp(cur_loss):8.2}')
total_loss = 0
start_time = time.time()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
ntokens = len(TEXT.vocab.stoi)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
data, targets = get_batch(data_source, i)
output = eval_model(data)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
best_val_loss = float("inf")
epochs = 3 # The number of epochs
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train()
val_loss = evaluate(model, val_data)
print('-' * 89)
print(f'| end of epoch {epoch:3} | time: {(time.time() - epoch_start_time):5.2}s | valid loss {val_loss:5.2} | '
f'valid ppl {math.exp(val_loss):8.2}')
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
scheduler.step()
Evaluate the model with the test dataset
최고 성능을 보이는 모델을 사용해 test dataset을 확인해봅니다.
1
2
3
4
test_loss = evaluate(best_model, test_data)
print('=' * 89)
print(f'| End of training | test loss {test_loss:5.2} | test ppl {math.exp(test_loss):8.2}')
print('=' * 89)
Leave a comment