
계층형 아키텍처 (Layer architecture)
들어가며
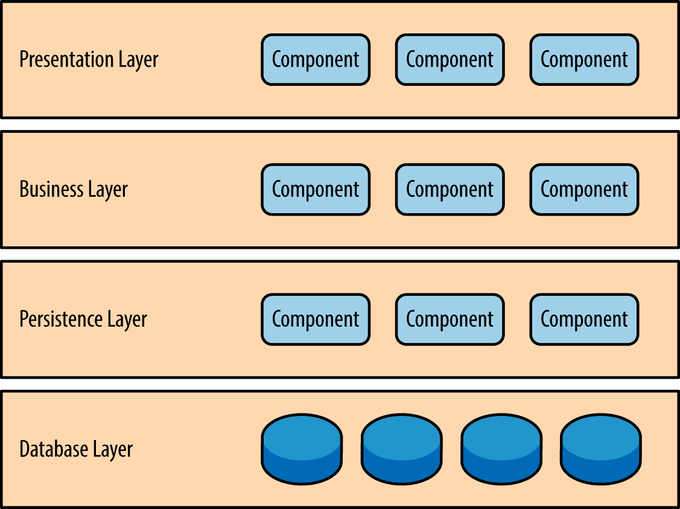
계층형 아키텍처(Layer architecture)는 소프트웨어 개발에서 가장 일반적으로 널리 사용되고 있는 아키텍처로, 소스코드의 역할과 관심사에 따라 이를 계층으로 분리하는 것이다. 각 계층은 어플리케이션 내에서의 특정 역할과 관심사(화면 표시, 비즈니스 로직 수행 및 DB작업 등) 별로 구분된다 (관심사의 분리).
여러 계층으로 분리함에 따라 개발자는 각 계층만을 집중하여 개발할 수 있으며, 시스템의 확장성과 유지보수성을 향상시킨다. 또한, 계층 간의 엄격한 분리는 보안 측면에서도 이점을 제공한다.
만일 계층을 분리하지 않는다면 어떻게 될까?
기술 및 시대가 변화함에 따라 윈도우 애플리케이션을 웹기반으로 변경해야하는 경우가 발생할 수도 있다. 만약 계층을 분리하지 않는 경우 주요 비즈니스 로직과 UI, DB 등이 모두 한 곳에서 관리되기 때문에 UI의 변경만으로 코드 전체를 새롭게 만들어야 되는 경우가 발생할 수도 있다. 마찬가지로 이는 React를 Vue로 전환한다거나 DB를 변경하는 등 좀 더 작은 범위의 교체에도 그대로 적용된다.
이제 각 계층에 대해 하나하나 살펴보도록 하자.
웹 계층 (Web layer, Presentation layer)
웹 계층(Web layer, 또는 프레젠테이션 계층 (Presentation layer))은 사용자와의 상호작용을 위한 계층으로, 웹 어플리케이션의 사용자 인터페이스와 관련된 로직을 담당한다. 따라서 웹 계층은 UI 또는 API Endpoint로 표현된다.
웹 계층에선 비즈니스 로직을 하지 않고, 오직 외부와의 인터페이스만 책임진다. 따라서 HTTP 요청을 받고 이 요칭을 서비스 계층(service layer)로 전달하는 역할을 한다.
주요 요소로는 Model, View와 controller (e.g. FastAPI endpoint)가 있다 (MVC (Model / View / Controller)).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from fastapi import APIRouter, HTTPException
from models.user_model import UserCreate
from services.user_service import UserService
from repositories.user_repo import UserRepository
router = APIRouter()
repo = UserRepository()
service = UserService(repo)
@router.post("/users")
def create_user(user: UserCreate):
try:
return service.register_user(user)
except ValueError as e:
raise HTTPException(status_code=400, detail=str(e))
위 예시를 보면 다음의 역할과 특징을 볼 수 있다:
- 외부 요청을 받고 결과를 응답함
- 요청을 검증하며 예외 처리만 담당 (로직은 서비스 계층으로 위임)
service.register_user()로 비즈니스 로직을 위임 → API 코드는 얇고 간결
웹 계층은 표현 계층(Presentation layer)이라고도 하는데, 컨트롤러가 요청/응답의 형식만 담당하고 (즉 외부와의 인터페이스를 정의하고 관리), 실제 처리 로직은 서비스 계층이나 도메인 계층에 위임하기 때문이다.
위 FastAPI의 @router.post(...)를 보면 API의 외형과 입출력 스펙만 선언하고, 실제 무엇을 하라는 코드는 작성하지 않았다.
이는 표현 책임만을 담당하는 구조의 대표적인 예로 볼 수 있다.
서비스 계층 (Service layer, Business layer)
서비스 계층(Service layer, 또는 비즈니스 계층 (Business layer))은 애플리케이션의 핵심이라 할 수 있다. 이 계층에선 핵심 업무 로직의 처리 방법 기술과 관련 데이터의 적합성을 검증한다. 또한, 트랜잭션을 관리 및 처리하며 위에서 살펴본 웹 계층와 아래에서 살펴볼 데이터 계층를 연결하는 역할을 한다. 서비스 계층은 재사용 가능한 비즈니스 로직을 구현하는데 초점을 두며, 여러 컨트롤러에서 호출될 수 있다.
회원가입을 예시로 들었을 때 서비스 계층은 다음과 같이 작성된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from repositories.user_repository import UserRepository
from models.user_model import UserCreate
class UserService:
def __init__(self, repo: UserRepository):
self.repo = repo
def register_user(self, user: UserCreate):
# 해당 메소드는 컨트롤러가 호출함
# 핵심규칙 1: 이메일 중복 금지
if self.repo.exists_by_email(user.email):
raise ValueError("이미 존재하는 이메일입니다.")
# 핵심규칙 2: 이름은 2자 이상이어야 함
if len(user.name.strip()) < 2:
raise ValueError("이름은 2자 이상이어야 합니다.")
# 저장
self.repo.save(user.dict())
return {"message": "회원가입 완료"}
어떤 로직이 도메인 로직인지 아닌지 구분하는 것은 꽤나 어려운 일이다. 이럴때는 마틴 파울러의 Patterns of Enterprise Application Architecture (PEAA)에 나온 방법을 사용하면 좋다.
“만약 이 애플리케이션을 CLI 또는 다른 저장 수단(XML 등)으로 바꿔도 해당 로직이 그대로 유지된다면, 그것은 도메인 로직이다.”
이를 자세히 살펴보면 다음과 같다:
- 애플리케이션의 핵심 규칙을 담고 있는가?
- 비즈니스 규칙, 계산 로직, 상태 전이 등 핵심 도메인에 대한 이해를 반영하는 로직인가?
- e.g. 주문 총액 계산, 결제 승인 여부 판단, 등급 승급 조건 등
- 입출력(I/O)이나 인프라와 독립적인가?
- UI, DB, 파일, 네트워크 등과는 무관한가?
- CLI나 XML 파일 기반 등 다른 환경으로 바뀌어도 그대로 유지될 수 있는가?
- 복사/중복 없이 다른 컨텍스트로 재사용 가능한가?
- 로직을 재사용하려 할 때, I/O나 프레젠테이션 계층을 복사하지 않아도 되는가?
도메인 계층 (Domain layer)
도메인 계층(Domain layer)는 서비스 계층에 포함되는 개념으로 비즈니스 로직에 대한 핵심 규칙을 담고있다. 반면, 서비스 계층은 전체적인 비즈니스 로직과 이에 따른 흐름, 핵심 규칙을 함께 포함한다.
위에서 본 예시코드의 경우 문제점은,
- 관심사 혼합: 흐름 제어 + 유효성 검사 + 저장을 담당하는 코드가 모두 한 곳에 있음
- 재사용성: 규칙을 다른 유스케이스에서 재사용하기 어려움
- 도메인 규칙이 흐름 속에 묻힘: 핵심 규칙이 눈에 띄지 않음
- 테스트 어려움: 규칙 하나하나에 대해 검증할 수 없고 비즈니스 로직 전체를 테스트해야함
가 된다.
이를 도메인 계층으로 분리하여 작성하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# domain/user_entity.py (도메인 계층)
class UserEntity:
def __init__(self, name: str, email: str):
self.name = name.strip()
self.email = email
self._validate()
def _validate(self):
# 핵심규칙 1: 이메일 중복 금지
if len(self.name) < 2:
raise ValueError("이름은 2자 이상이어야 합니다.")
def check_email_duplicate(self, existing_emails: list[str]):
# 핵심규칙 2: 이름은 2자 이상이어야 함
if self.email in existing_emails:
raise ValueError("이미 존재하는 이메일입니다.")
우선 핵심 규칙만 따로 분리하여 도메인 객체 내부에 넣어놓는다. 이는 객체가 생성될 때 자동으로 검증되며, 중복 이메일 검사는 메서드로 만들어 외부에서 호출이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# application/user_service.py (비즈니스 계층)
from domain.user_entity import UserEntity
from repositories.user_repository import UserRepository
from models.user_model import UserCreate
class UserService:
def __init__(self, repo: UserRepository):
self.repo = repo
def register_user(self, user_data: UserCreate):
# 도메인 객체 생성 → 내부에서 이름 유효성 검증 수행됨
user = UserEntity(name=user_data.name, email=user_data.email)
# 중복 이메일 확인
existing_emails = self.repo.get_all_emails()
user.check_email_duplicate(existing_emails)
# 저장
self.repo.save(user.__dict__)
return {"message": "회원가입 완료"}
이후 서비스 계층에서는 흐름만 담당한다 (입력 → 도메인 → 저장).
모델 계층 (Model layer)
모델 계층(Model layer)은 데이터의 구조와 형태 정의한다. Pydantic이나 ORM 모델을 생각하면 된다.
1
2
3
4
5
6
# models/user_model.py
from pydantic import BaseModel
class UserCreate(BaseModel):
name: str
email: str
데이터 계층 (Data access layer, Repository layer, Persistent layer)
데이터 계층(Data access layer 혹은 레포지토리 계층 (Repository layer))은 모든 DB 관련 로직을 처리한다 (CRUD). DB에 접근하는 DAO 객체를 사용할 수도 있다.
마무리
유저의 입력부터 위에서 살펴본 각 계층으로의 호출을 차례대로 정리하면 다음과 같다:
- 사용자가 API 호출 → Presentation Layer
- 컨트롤러가 요청 파싱 후 → Application Layer
- 서비스 계층이 비즈니스 로직 처리
- 리포지토리 통해 DB에 저장 → Persistence Layer
- 결과 응답 생성 → 위 계층으로 전달
이렇듯 계층은 수직적으로 배치가 되어 특정 계층는 바로 하위 계층에만 연결된다.
그렇다면 웹 계층에서 바로 데이터 계층에 연결해서 정보를 가져오는 건 어떨까? 만약 웹 계층에서 직접 DB에 접속해서 데이터를 가져오게 되면 SQL에 대한 변경사항이 웹 계층에 바로 영향을 미치게 된다. 이는 과도한 의존성이 발생하게 되는 것으로, 애플리케이션의 변경을 어렵게 만든다. 계층화 구조에서 각 계층는 캡슐화 되어있다. 각각의 계층은 다른 계층과 독립적이기 때문에 다른 계층의 내부 동작을 모르게 된다. 따라서 다른 계층에 영향을 주지않고 변경될 수 있다.
다음은 계층형 아키텍처를 도입함에 따른 장점이다
- 관심사 분리 (Separation of Concerns): 코드 간 관심사를 분리하여 한 계층의 변경이 다른 계층에 영향을 미치지 않도록 함.
- 재활용성: 코드의 응집도가 높아져서 재사용성, 유지보수성, 확장성이 향상되며 다른 애플리케이션에서 재활용이 가능
- 테스트 용이성: 각 계층별로 테스트가 가능
그러나 계층형 아키텍처를 도입하는 것이 만능은 아닌데, 계층 간의 의존성으로 인해 하나의 계층에 변경이 발생할 경우 상위 혹은 하위 계층에도 영향을 미칠 수 있으며, 이로인해 유지보수의 복잡성을 증가하는 경우가 발생한다.
또한, 계층형 아키텍처 구조에 따라 소프트웨어가 핵심적으로 해결하고자 하는 문제영역으로서 도메인이 아니라 Data-Access 계층, 즉 DB가 소프트웨어의 핵심이 될 수 밖에 없다. 즉, DB 모델을 먼저 정의한 후 리포지토리 → 서비스 → 컨트롤러를 얹는 방식으로 개발된다. 이로인해 “이 시스템이 무슨 문제를 해결하려는가?”보다 “DB에 어떻게 저장할 것인가?”가 중심이 된다. 또한, DB에서 컬럼이 변경되거나 다른 DBMS로 변경되는 등 DB 계층에서의 변경사항이 서비스 계층에 영향을 미치는 경우가 빈번하게 발생한다.
결과적으로 도메인이 설계에서 멀어져 도메인의 개념, 규칙, 상태 전이 등은 신경쓰지 못하고 DB에 무엇을 저장할지만 고민하게 되는 현상이 발생한다. 그래서 DDD나 클린 아키텍처에서는 도메인이 중심이 되는 구조(예: 유스케이스 중심, 도메인 엔티티 우선)를 강조하는 경우가 있다.
Leave a comment